
I got into semantic SEO while overseeing major client accounts for SEMrush, partnering with semantic content optimization companies, and overseeing more than 9 large data studies for NeilPatel.com in the past 5 months. Here’s what a learned.

A revolution? Really? There are massive changes in how Google uses machine learning with exponential success, so yes. Google Translate famously killed it (or should I say, “killed” the non-machine learning, traditional computer programming engineers) by using machine learning to improve results. Google does not share much about these new AI techniques in their flagship product, Search, as they don’t want to let the SEO community in on secret sauce. Keywords on webpages have the same qualities for machine learning as in text typed into translation software.
Last fall, Neil Patel asked me to oversee one research study per week to provide actionable information for his website readers. My first piece for him was about Google’s Hummingbird algorithm which is at the core of its semantic self-learning algo. My second piece for him was about top tools used to “backwards analyze” Google’s semantic search algorithms. I don’t just find this subject interesting: No, it’s infinitely important to marketers and endlessly fascinating to me!
Primer: Role of Keywords vs. Topics
To rank high with Google’s hugely important Hummingbird algorithm, make sure you cover all relevant, related ideas/topics/entities thoroughly and holistically.
Google does not look at keywords as variables for ranking. If you misspell a word you do NOT have a better chance of ranking! However, if you mis-spell and do exact-match bidding for AdWords you have a lot to gain.
Using phrases-match, by itself, and “related keywords” tools is not a good way to do research for content strategy and SEO. (Phrase match is defined by Google as “when someone’s search includes the exact phrase of your keyword, or close variations of the exact phrase of your keyword, with additional words before or after. “)
You need to find the degree of relevance with related keywords. This degree of relatedness comes from semantic analysis (note: it’s also referred to as “natural language processing”).
Of course, Google also uses “structured data” in its semantic algorithms. This is especially used for the knowledge graph panels. It comes, for example, from “rich snippet” mark-ups on your web pages. It is not what we’re covering here, as our focus is the non-structured which you can optimize for higher search rank and the thorough topic coverage your website readers demand.
Keyword phrases and topic phrases are represented by a group of words, but the context with which the word groups that are discussed is what dictates the label used. “Topic” is used in the world of semantic analysis when we’re talking about precise relationships. “Entity” is another popular word used for these discussions. Topics and entities must have definable characteristics. Otherwise, there is no way to empirically find relationships.
Topic Modeling
Topic modeling as a field has its origins in the work of Francis Galton (1822-1911) who was an English Victorian polymath and statistician known for his pioneering work on biostatistics, differential psychology and meteorology.
Galton’s first book was Natural Inheritance (1889), which introduced several fundamental concepts including correlation calculated from pooled variance with weighted regression toward the mean. Pooled variance is similar to modern cohort analysis for longitudinal data or mixed models for repeated measures with time-varying covariates.
Topic modeling is a mathematical and computer science technique used for discovering the abstract ‘topics’ which occur in a collection of documents. It does this by considering associations between words. The result of topic modeling is a model, or map, of semantic structures contained in the set of documents at hand.
The idea of topic modeling is to discover the main topics that a collection of documents are about. This can be useful because it gives us insight into what the author was trying to say, and how he or she was trying to present their ideas.
We can use topic modeling on this document, for example, to find which topics are most commonly discussed.
Google Keyword Planner Fails For Organic Keyword and Topic Research
Google Keyword Planner (meant for AdWords customers, but used by beginner SEOs and some content creators to research keywords) sets out to group their related keywords by relevance. Why don’t they use the same brilliant topic matches we see in their search engine to power related terms?
Have a look at the below results from Moz Keyword Tool topic results vs. Google KW planner. The salmon-colored words are found in both tools. The parent keyword/topic is “internet speed test.” The scores to the right show the degree of confidence Moz has in how related the other topics are to our primary topic.
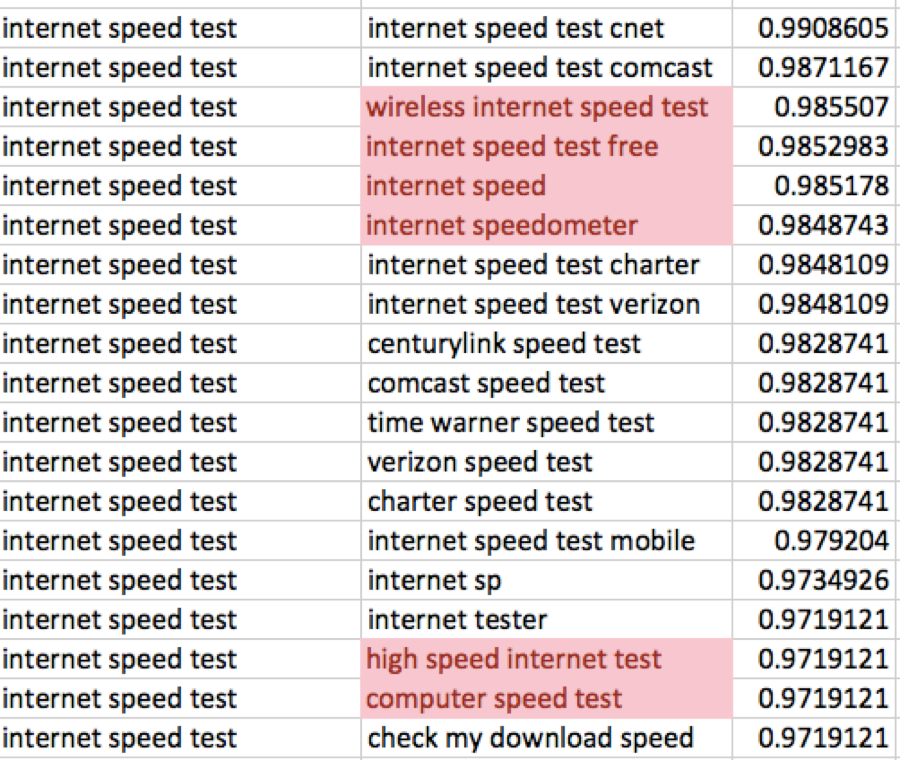
We know a key issue with results in Google Keyword Planner is they are appealing to customers looking to reach searchers with commercial intent (otherwise people wouldn’t pay money). So the results from their tool mention a lot of brands (RE: Comcast or Time Warner).
However, Google is not going to provide keyword information to those looking for organic results, and in this case, they do not want show branded keywords too much and encourage competitors to cannibalize on each other. The world is made up of brands, perhaps more than most of us realize. When google strips out proper nouns and brands from their tool, it loses usefulness for organic keyword research.
Google Trends Doesn’t Do Topics
Google also doesn’t provide nuanced, precise data in their “Trends” product. For example, in the Trends tool, Google say “Users searching for your term also searched for these topics.”
This seems a bit opaque. They show categories of similar topics, but these are very broad topics they match to a specific search. Do those that search for “California secretary of state” really do a search for “California” which Google returns as “Users searching for….”? I doubt that someone interested in a broad search term with only the state name is also ready to dig into the specifics of the Secretary of State’s office or records. Either Google doesn’t want to reveal their incredible machine learning results from their Search product, or some of their “Trends” work is simply of B-league quality.
The Rise Of Semantic Optimization Software: Moz, SEMrush, And MarketMuse
The two leading, non-enterprise level tools for semantic analysis are Moz Keyword Explorer and SEMrush. Both cost a fraction of enterprise software for topic modeling but are also very limited unless you fully understand all subjects you are writing about and you have under 1000 web pages. The space for advanced tools is led by Search Metrics and MarketMuse, both of which are worth paying an agency to use on your behalf. Moz and SEMrush backward analyze Google SERP and other sources to find related topics.
To understand what Moz can tell us, I started with 1000 keywords to research the topics Moz Keyword Explorer produces. 150 results were extracted for each, producing a total of 150,000 related topics. Here’s what Russ Jones, Principal Search Scientist for Moz, told me about the topic research capabilities of the tool.
“Our suggestions come from several sources, starting with our primary keyword data set that was built from Google KWP, Bing Keyword Data, Google, Yahoo and Bing Suggestions, and clickstream data from 2 different.
This is how we built such a large corpus (over 2 billion keywords originally). So, starting off, we definitely have a larger corpus to draw from. Moreover, Google Keyword Planner doesn’t show you all the keywords, of course, when you get recommendations. You get a sampling of keywords that they think are likely to be ad opportunities. This creates gaps in the data they provide.
We also have several algorithms for finding related terms. This involves everything from basic phrase matching, SERP mapping, stemming, and semantic algorithms. This gives us candidates words which can then be scored on relevancy and displayed in the appropriate order in our system. Long story short, our keyword suggestions and relevancy measurements are a complex array of technologies that maximize the diversity and quality of keywords returned.”
A full 1/3 of all topics in the 150,00 results were phrase matches to their parent topic. I’ve seen this with other topic research and this is exactly why keywords are not dead as so many hpysters would have you believe: matches of exact words are critical to adequately phrase-relate similar or parent topics.
Example:
| Primary Keyword | Related Keyword from Moz | Phrases Match? |
| 2015 nfl standings | final 2015 nfl standings | TRUE |
| stevens institute of technology | stevens institute of technology mba program | TRUE |
Phrase matches are useful, but we need to also know relevance or they lose their usefulness. For example, “paypal” vs. “pay and pal” is one that has a degree of confidence in the tool, BUT most of the results for “paypal” also have that exact spelling and word in the related keyword/topic. Also, a full 1/3 of what we examined were “head” keywords. These are very often one-word terms. Clearly, related topics will have the one-word but then add other words which characterize the topic.
I also spoke with SEMrush, and here’s their description for their “Degree of Relevance” in their “Related Keywords Report”
“It’s pretty darn accurate because we’re essentially letting Google’s algorithms do the work for us. We simply scale the likelihood of ranking for one term if you rank for another. For example, a close variation or misspelling. We do this by analyzing what keywords a URL ranks for as opposed to a root domain overall. If a URL ranks for X term, they may also rank for that close variation or misspelling. Now, when you see similar patterns among multiple URLs, it only serves to strengthen the belief that they’re semantically related.”
Conclusion
There’s a lot of misinformation about the role of “keywords” today. Historically, search engines were reliant on variants of words, but today the Web is about more complex, semantic relationships, and Google is leading the charge. Writing topic modeling algorithms seen in enterprise software or in Google Hummingbird requires intelligence associated with a rocket scientist. Using techniques and software to actually do topic modeling does not require a PhD! It does, however, help if you have a lot of experience in content planning and SEO. If you are using non-enterprise software, you’ll need a process to string topics together across your website. Or, hire an SEO expert that uses advanced tactics with the software tools.
Please contact Van Buskirk to tighten the topic relevancy of your website. He’s recognized globally for his semantic optimization expertise.